当前文章并没有写完
谷歌论文zanzibar的 rust 实现
zanzibar 是谷歌全球授权系统的实现,但谷歌并没有开源,只是发布了一篇论文来秀,近些年,也有很多优秀的实现,比如:
- https://github.com/openfga/openfga auth0开源的,现在已经捐给 cncf,现为沙盒项目
- https://github.com/Permify/permify 貌似是国外创业小厂实现,我自己感觉比 openfga 要好一点,因为他可以展开 users,而 openfga 不行
- https://github.com/authzed/spicedb 没仔细看他的实现,就不发表评价了
他们三个的共同点是都基本实现了 zanzibar,都没有 index system,表达式引擎都是用的 https://github.com/google/cel-go
写这个 rust 版本的目的并不是为了能与大佬们分一杯羹,相反,通过自己写 rust 版本,从而会看他们大量的文档、设计和代码实现,最后能更好的使用他们。
库选型
解析器
思来想去还是自己写了,openfga 的语法并不是我想要的,所以就用lalrpop自己写一个吧,但是 lex 是自己写的
通讯协议
HTTP
GRPC
需要自己写lb:tonic-lb (发布两天竟然有260+下载量,虽然可能是镜像站或机器人下载的,但还是超级开心)
ORM/db mapping
表达式引擎
选择了一个脚本语言,而不是传统的表达式计算引擎。
在 rust 现有生态里,只有一个 evalexpr 看起来还不错,但是支持的类型太少了,而且在 eval 的代码是类型硬编码,不好拓展,不想花太长时间来捣鼓。
然后就找到了rhai,因为他的 about 就是:”Rhai - An embedded scripting language for Rust.”,那就看看他的魔法吧
Schema的设计
借鉴已有实现的优秀设计,一个 authz_model 可能是这样的:
// define user type, no relation, no permission
type user {}
// define group type, has a relation
type group {
member: user
}
// define group type, has some relations and some permissions
type folder {
relation owner: user
relation parent: folder
relation viewer: user | user#* | group#member
permission view: viewer + owner + parent#viewer
}
type xx {
relation a: user with check_ipaddress
permission b: a with check_age
}
解释:
- 使用
//作为注释开始符号 - 使用 type 关键字来定义一个实体
- 一个实体内有 relation 和 permission 两种关系: 1. relation 类型的关系只能使用实体或实体内部relation; 2.permission 可以定义更复杂的关系,通过使用()(增加优先级), +(或), -(排除), & (并集)
- relation 和 permission 都可以使用 with 关键字来加载条件(Condition),一个条件对应 rhai 的一个方法
- 在其他的设计中,都会把condition 的定义放在autzhz_model 的定义里,这里我为了简单,把他单独存放,这样做也有好处:定义更清晰,易于 debug。当然缺点也显而易见,维护困难,为了解决这个问题,可以从 playground 上增加可用性。
数据库表设计
没加表达式引擎之前的设计
relation_tuples(id, tenant_id, model_id, object_type, object_id, relation, user_type, user_id, user_relation)
authz_models(id, tenant_id, model)
tenants(id, name)
加表达式引擎之后的设计
有三种可选的设计:
- 直接把 attributes 加入relation_tuples里的字段:relation_tuples(id, tenant_id, model_id, object_type, object_id, relation, user_type, user_id, user_relation, attributes)
- 单独建一张表,但把attributes作为一个字段存:tuple_attributes(id, tuple_id, attributes)
- 单独建一张表,把 attribute 打平:tuple_attributes(id, tuple_id, key, value),但如果value 是 json 字段,那这种设计就画蛇添足了,除非这样tuple_attributes(id, tuple_id, key, key_type, value)加一个 key_type 来区分类型但这样也解决不了数组问题
综上所述,还是第一种办法简单粗暴
回顾permify check流程
请求:
{
"metadata": {
"schema_version": "",
"snap_token": "",
"depth": 20
},
"entity": {
"type": "organization",
"id": "1"
},
"permission": "delete_files",
"subject": {
"type": "user",
"id": "1",
"relation": ""
}
}
- 获取实体定义
entity organization {
relation admin @user
relation member @user
permission view_files = (admin or member)
permission edit_files = admin
permission delete_files = admin
}
- 进入checkLeaf->checkComputedUserSet
- 转化请求
{
"metadata": {
"schema_version": "",
"snap_token": "",
"depth": 20
},
"entity": {
"type": "organization",
"id": "1"
},
"permission": "admin",
"subject": {
"type": "user",
"id": "1",
"relation": ""
}
}
- 进入checkDirectRelation,校验权限
SELECT
entity_type,
entity_id,
relation,
subject_type,
subject_id,
subject_relation
FROM
relation_tuples
WHERE
tenant_id = 't1'
AND entity_id IN ( '*','1' )
AND entity_type = 'organization'
AND relation = 'admin'
AND ( pg_visible_in_snapshot ( created_tx_id, ( SELECT snapshot FROM transactions WHERE ID = '100090072' :: xid8 ) ) = TRUE OR created_tx_id = '100090072' :: xid8 )
AND (
( pg_visible_in_snapshot ( expired_tx_id, ( SELECT snapshot FROM transactions WHERE ID = '100090072' :: xid8 ) ) = FALSE OR expired_tx_id = '0' :: xid8 )
AND expired_tx_id <> '100090072' :: xid8
)
- 遍历元组集
- 如果subject_type + subject_id == subject,则返回允许
- 进一步转化请求,
{
"metadata": {
"schema_version": "",
"snap_token": "",
"depth": 20
},
"entity": {
"type": "##subject_type",
"id": "##subject_id"
},
"permission": "##subject_relation",
"subject": {
"type": "user",
"id": "1",
"relation": ""
}
}
模块设计
check
核心检查器,定义检查器接口,有四种实现,分别为:
- local(执行检查任务),
- cache(缓存检查结果),
- remote(远程lb检查,由local分解tuple内容,然后分发至remote执行),
- cycle(环形tuple检测)
local check检查流程
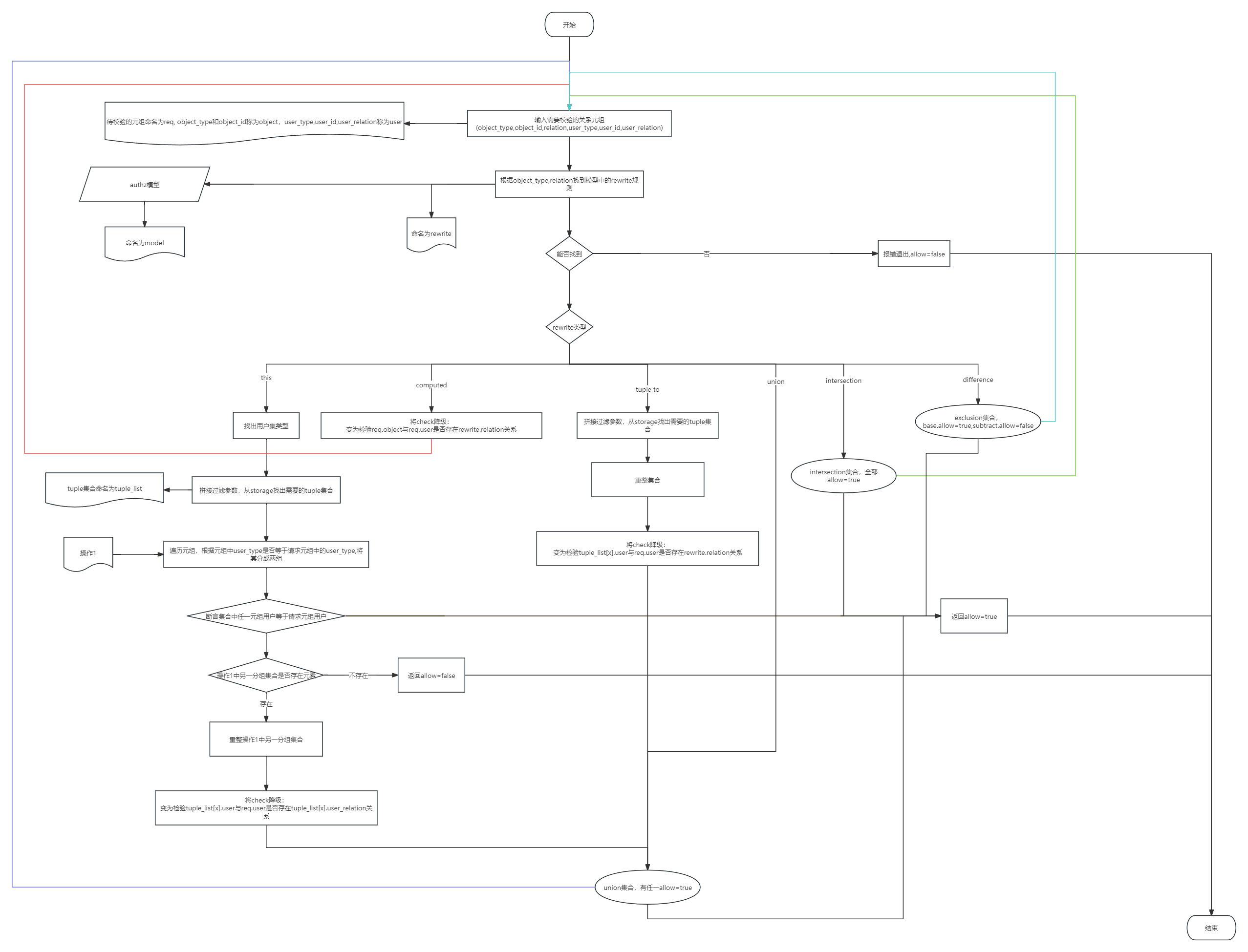
假设授权模型
type user {}
type group {
relation member: user
}
type folder {
relation parent: folder
relation viewer: user | group#member
permission can_view: viewer | parent#can_view
}
预设关系元组
group:1 member user:1
folder:1 viewer group:1#member
预设请求 1
folder:1 viewer user:1
说明
- 当一个请求进来以后,先找到 授权模型,并将其转化为 typesystem,方便 checker 后续使用
- 首先根据 tuple中的 object_type 和 relation 找到 rewrite 规则:this,compute,ttu
- 在预设请求 1 中,得到的 rewrite 为:this
storage
提供存储服务,包括:
- tuple读写,
- authz model读写,
- tenant读写
server
提供http服务和grpc服务,提供的接口:
Zanzibar的接口
- read
- write
- watch:暂不实现
- check
- expand
权限模型crud接口
租户crud接口
考虑抽象api通用层,http和grpc都是用api来提供服务
authz model
权限模型的定义,dsl写法目前先参考openfga
后续优化模型
现有实现的缺陷
openfga
- 不能解决管理员问题,即用户x拥有所有doc的某种relation
- 数据库定义没有将object_type,object_id,relation,user_type,user_id,user_relation区分,导致代码有很多不必要的判断和切分
- 没有实现Leopard Indexing System,没有watch
permify
- 不能解决管理员问题,即用户x拥有所有doc的某种relation
- schema定义的relation需要区分relation/action
- schema不能转译成 json,下游应用很难写维护页面
- 没有实现Leopard Indexing System,watch功能使用应用程序实现,而不是从数据库提供
展开objects
objects({ot=folder, r=view, ut=user, ui=1})
找到相应relation
user
group { member: user }
folder {
viewer: user | group#member
parent: folder
view: viewer | parent#view
}
direct → direct_objects
1. 类型相同
select * from tuple where ot = folder and r = viewer and ut = user and ui = '1'
2. 类型不同,无 user_relation, continue
3. 类型不同,存在 user_relation
- 判断这个 object是否存在 user 关系
- 如果存在
mid_object_ids = self.direct_objects({ot=group, r=member, ut=user, ui=1})
object_ids = select * from tuple
where ot = folder and r = viewer and ut = group and ui in mid_object_ids
computed
// source: objects({ot=folder, r=view, ut=user, ui=1})
objects({ot=folder, r=viewer, ut=user, ui=1})
tuple to userset
// source: objects({ot=folder, r=view, ut=user, ui=1})
mid_object_ids = self.direct_objects({ot=folder, r=view, ut=user, ui=1})
object_ids = select * from tuple
where ot = folder and r = parent and ut = folder and ui in mid_object_ids
展开users 类似,就不再冗余介绍了