git基础知识
.git目录探索
tree -L 1 .git/
.git/
├── COMMIT_EDITMSG — 最近一次commit的msg
├── HEAD — 当前头指针
├── ORIG_HEAD — 远端头指针
├── config — 项目git配置
├── description — GitWeb使用
├── hooks — client或server钩子脚本
├── index — 暂存区索引
├── info — 保存项目全局需要排除的ignored patterns(很神奇的用法是:如果需要不在.gitignore文件中追踪,但需要忽略的文件,可以通过修改这个文件来实现)
├── logs — 非初始化目录,记录一切修改HEAD的操作
├── objects — 相当于git的数据库,使用sha-1校验和作为文件名,文件内容使用zip压缩
└── refs — 维护分支和tag的引用关系
git中的对象(object: blob, tree, commit) 及sha-1校验和的由来
blob
项目目录下除了被忽略的文件和.git目录下的文件,其余的文件就是一个blob对象。
➜ test-git git:(main) echo 'hello git' > hello
➜ test-git git:(main) ✗ git add hello
➜ test-git git:(main) ✗ find .git/objects -type f
.git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
可以看到,在git add 以后,文件即保存在git存储里。
8d/0e41234f24b6da002d962a26c2495ea16a425f这一串sha-1是如何生成的呢?git暴露出了一个sub cli可以生成hash:
➜ test-git git:(main) ✗ echo 'hello git' | git hash-object -w --stdin
8d0e41234f24b6da002d962a26c2495ea16a425f
hash-object命令就是对输入的字符计算sha-1校验和,也可以在自己的电脑上用熟悉的语言打印一下是否如此(这个操作git有夹藏私货:需要格式化文件,如下)。
我们强行查看一下这个对象文件里究竟有什么
➜ test-git git:(main) ✗ cat .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
xK��OR04`�H���WH�,�6A�%
不出所料是一串乱码。使用zlib-reader阅读一下里面究竟有什么
➜ test-git git:(main) ✗ zlib-reader .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
"blob 10\x00hello git\n"
查看资料可以抽象出文件内容的格式:
x00
使用git提供的方式格式化阅读:
➜ test-git git:(main) git cat-file -p 8d0e41234f24b6da002d962a26c2495ea16a425f
hello git
➜ test-git git:(main) git cat-file -t 8d0e41234f24b6da002d962a26c2495ea16a425f
blob
tree
刚才只是在项目顶级目录创建了文件hello,现在尝试建立子目录:
➜ test-git git:(main) ✗ mkdir topic
➜ test-git git:(main) ✗ echo 'hello topic' > topic/hello-topic
➜ test-git git:(main) ✗ tree -L 2 .
.
├── hello
└── topic
└── hello-topic
1 directory, 2 files
➜ test-git git:(main) ✗ git add topic/hello-topic
➜ test-git git:(main) ✗ git write-tree
313d4544c5e56d50d88efc84043df5b7fe6fef69
➜ test-git git:(main) ✗ find .git/objects -type f
.git/objects/e4/1f889718a3d72c8538078bd07ac77334bb32ee
.git/objects/28/aeecdf471111ef079cbd8704f6db14f39a6a3a
.git/objects/31/3d4544c5e56d50d88efc84043df5b7fe6fef69
.git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
在未commit之前,是不会构建tree对象的,所以这里使用write-tree手动创建tree
查看他的格式化内容:
➜ test-git git:(main) ✗ git cat-file -p 313d4544c5e56d50d88efc84043df5b7fe6fef69
100644 blob 8d0e41234f24b6da002d962a26c2495ea16a425f hello
040000 tree e41f889718a3d72c8538078bd07ac77334bb32ee topic
抽象出内容的格式:
其sha-1的计算也是对文件未压缩前的内容进行hash
官网中的图例:
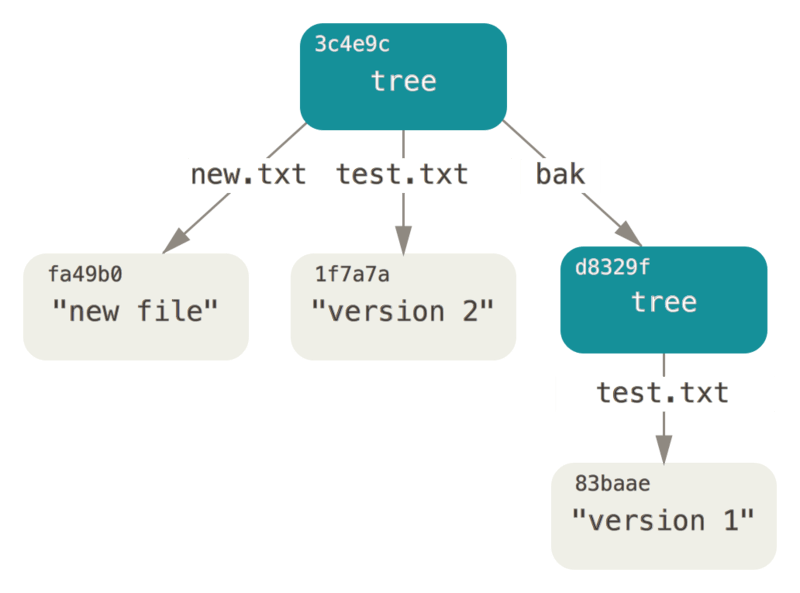
如图所示,tree对象确实是一棵树,且叶子节点为具体的文件,叶子必不能是tree,这也是为什么git不能追踪空目录的原因。
commit
每一次的commit也是一个git object,属于commit类型,看看他有什么内容:
➜ test-git git:(main) ✗ git commit -m 'first commit'
[main (root-commit) fa4cc5d] first commit
2 files changed, 2 insertions(+)
create mode 100644 hello
create mode 100644 topic/hello-topic
➜ test-git git:(main) git cat-file -p fa4cc5d
tree 313d4544c5e56d50d88efc84043df5b7fe6fef69
author yoogo <yoogoc@163.com> 1666081939 +0800
committer yoogo <yoogoc@163.com> 1666081939 +0800
first commit
抽象出文件内容的格式:
tree
author «email»
committer «email»
其sha-1的计算也是对未压缩前的文件内容进行hash,因为有时间戳的关系,同样的changes,在不同的时间计算出的sha-1是不同的。
我们看到tree 313d4544c5e56d50d88efc84043df5b7fe6fef69这就是树的根节点,官网图例:
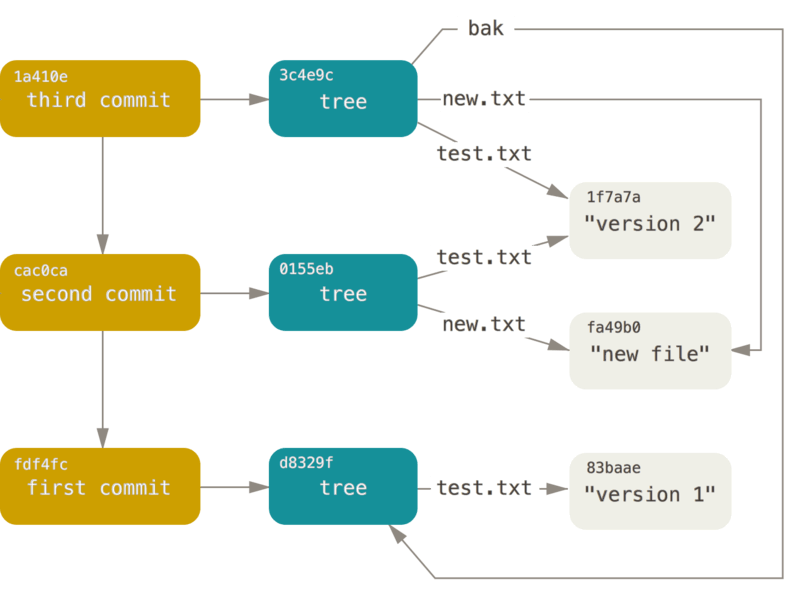
在这个图中,可以看到:
first commit提交了test.txt文件
second commit 提交了new.txt,并且修改了test.txt
third commit提交bak/test.txt,此次提交并未新增blob对象,因为new.txt,test.txt并未修改,所以得到的sha-1是相同的,提交的bak/test.txt内容与first commit的test.txt文件是相同的,所以计算出的sha-1也是相同的,所以都无需创建blob对象,只需构建tree即可。
事实上,所有的git操作都是围绕着这三个对象,所以理解git object是很重要的。
参考资料
https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
https://thoughtbot.com/blog/rebuilding-git-in-ruby
http://gitlet.maryrosecook.com/docs/gitlet.html
一些抖机灵的操作
git commit —-amend背景:接到需求,编码,git提交,发现一个小问题 这时提交到git可能的方案:对这个小问题新建一个commit。 但这种貌似不是很优雅,这样会使整个git log非常难看,过了n天,自己也记不得当时为什么在极短的时间差提交了两个commit,一个feat: xxxx,一个fix: xxxxx。 这时可以使用标题的操作,会把当前的更改替换到头指针的commit,新的提交具有与当前提交有相同的parent和author,相当于git reset --soft HEAD^, do something,git commit -c ORIG_HEADgit reflog搭配git reset背景:在刚才操作的基础上,发现我的fix是多余的,只是脑子抽风而已 这个时候可能会git reset --soft HEAD^, revert recent changes,git commit -c ORIG_HEAD这时可以用git reflog看看我究竟都对.git/HEAD做了什么,然后可以发现我的抽风发生在HEAD@{0},要是有一种办法帮我复原到HEAD@{1}就好了:git reset HEAD@{1}git cat-file上文已经用过很多次了,用来解析git sha-1值中的内容git apply在某些情况下,我不想commit,但是我还想与其他小伙伴分享我的代码,手动方式: 复制git diff的内容,保存并发送文件changes.diff,然后小伙伴逐行比对,手工变更, 这个时候就可以:git apply /changes.diff,会自动应用变更
更多cli参见
git —help -a,git —help -g
git commit建议
Atomic Commit
一个commit只做一件事(有点像数据库中事务的原子性)。例如,有两个不同的fix,应该提交两个commit,而不是fix a and fix b。为什么:
- 倘若你的fix在本地有生效,然而在staging或者prod并没有生效,假如在两个fix在一个commit,你可能的解决办法是:注释掉其中一个fix再提交一个commit或者amend到上个commit。但无论怎样都是无法先上线其中一个fix的;
- 假如两个fix在分别的commit上,那我们就可以git cp一个正常的fix先上线,再回过头修另外一个。
(换成不同的场景也是类似)
从而带来的好处:
- 让团队的其他人或者n天后的自己能尽快熟悉代码
- 方便出错时回滚
Don’t Commit Half-Done Work
一件事在同一人的同一阶段不要分为多个commit,这样会使commit message不堪入目,而且具有迷惑性,不符合直觉。实际的影响可能会在合并上游代码发生冲突,发生在你的commit part 1,这时你并一定不能够解决问题,因为他是个半成品,可能无法debug。
Write Good Commit Messages
要写一个概括性且准确的message,一定要保证准确,可以牺牲概括性。一个message可以分为如下几个部分:
- 变更的动机是什么?fix?feat?……
- 与之前的实现有什么不同?